Every module within the PAL software has its own individual revision number, this was briefly referred to in Section 3.4, when discussing the tags of a secondary commit. Each secondary commit on a development branch has a tag in the form:
SNNNNb-nnn.amm
Where SNNNNb is the first part of the branch name (before the dash), see Section 3.3. This is the originating master branch primary commit point (the SNNNN) from which the development branch diverges and the branch ordinal character, b, (this will be A for the first, B for the second &c.).
The remaining characters (nnn.amm) reflect the individual revision number of the module being developed. The six digits are all decimal numerals.
The numbering of the revision nnn.amm is an incremental numbering system. In this system nnn reflects the current version of the software; typically, the first properly released software will be 001. Previous development versions will be 000.
The numbers after the decimal point (amm) reflect development and test modification to the current revision (for software modifications), in this system a reflects the current status of the software as follows:
First digit (a)
Meaning
Description
0
Released mm will be 00
Code is released at version nnn (i.e. nnn.000)
1-7
Development
Code is under development and has not been tested
8
Proving (test)
Proving (test) revisions of the software
9
Qualification
Software is deployed to site and is being commissioned or qualified
Table 3.2 Software revision number (first digit)
The remaining numbers (mm), are incremental build numbers for the current revision (this allows development tracking).
A release version of the software will have revision 001.000, 002.000, 003.000 &c. I.e. the numbers after the decimal point are all zero. The first development of the software at release 003 would have revision 003.101.
3.6.1
Recording revision numbers within a programmable block
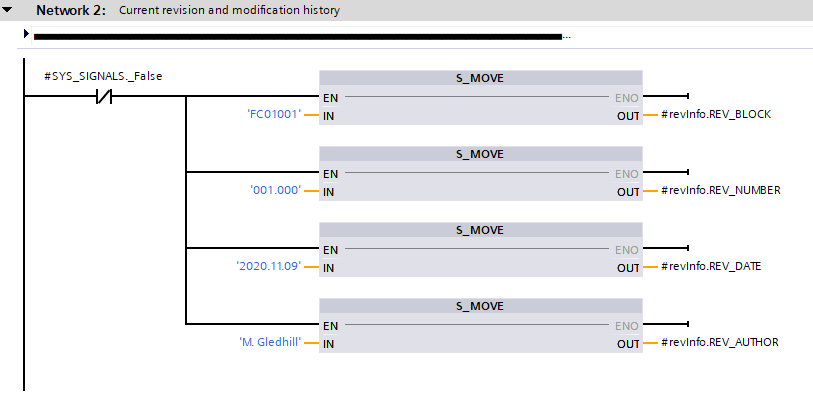
All programmable blocks (with the exception of OB1, see § 3.7) have the current revision number stored in the first non-empty network (usually network 2, sometimes network 3 for blocks with a large, textual block descriptions) of the block.
The revision number is both hardcoded in the block and is stored (with additional information) within the network comments of that network.
Hardcoded module revision data
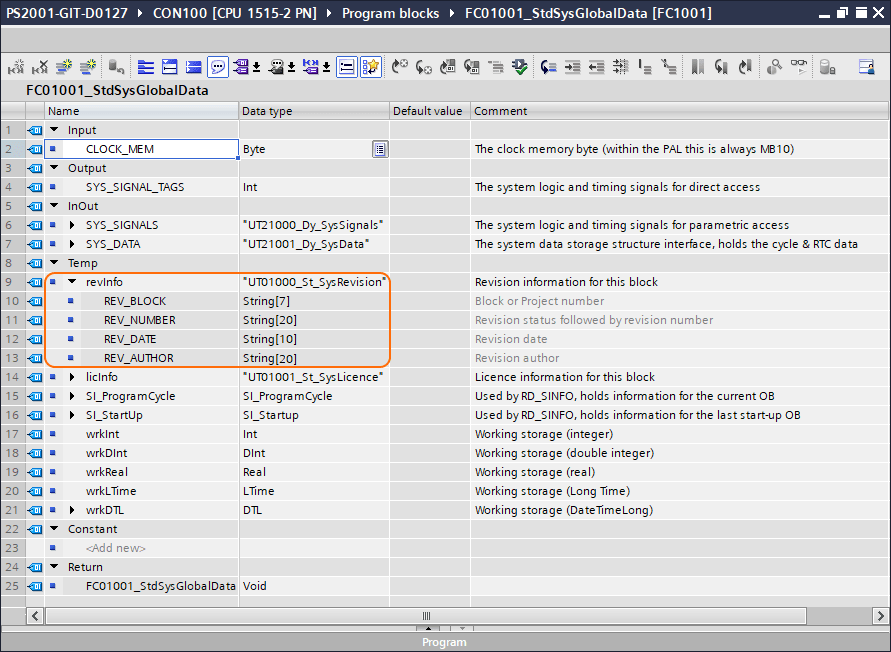
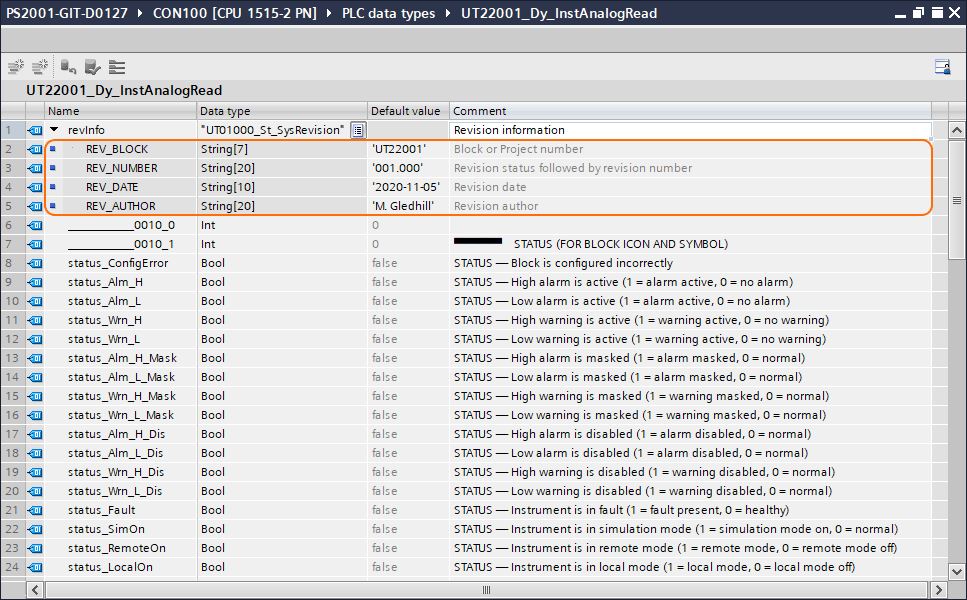
The hardcoded information is stored internally within the temporary area of the block as variable revInfo, this is of the user data type: UT01000_St_SysRevision:
Data Structure
UT01000_St_SysRevision
Signal
Type
Description
REV_BLOCK
String[7]
Block number (of this block)
REV_NUMBER
String[20]
Revision status and by revision number (for this block)
REV_DATE
String[7]
Revision date in format YYYY-MM-DD
REV_AUTHOR
String[20]
Revision author (initial and surname) or username
Table 3.3 Data structure: UT01000_St_SysRevision
The purpose of this is to hardcode in a recoverable format the basic, necessary revision data of the particular module (hardcoded information will always be present and recoverable from the Controller, even if the code comments are lost):
Block ID (the unique number of the block in question)
Revision number (incorporating status information)
Revision date
Revision author
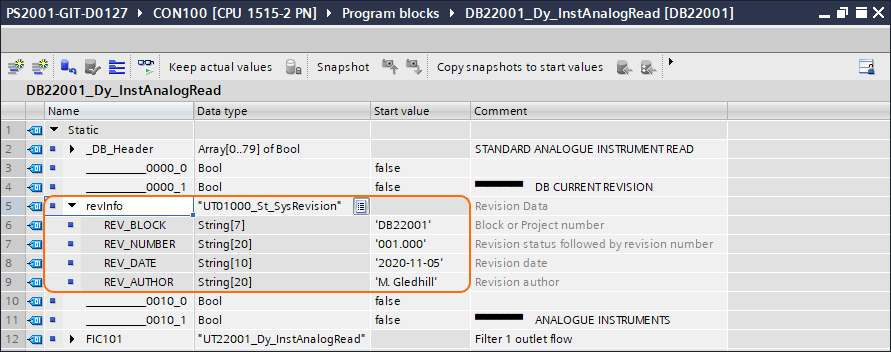
An example of this is shown below:
Figure 3.8 Block hardcoded revision information
The temporary variable revInfo is part of the block interface and is common to all PAL software modules (it must be defined and be present for all blocks within the PAL), an example is shown below:
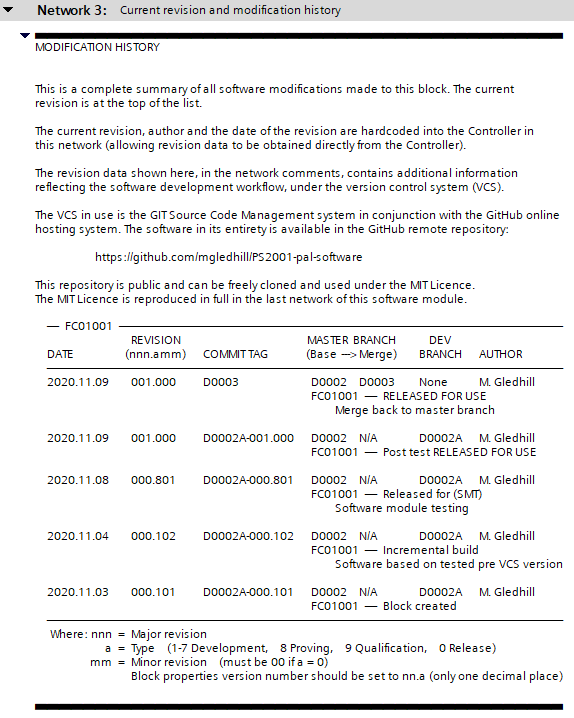
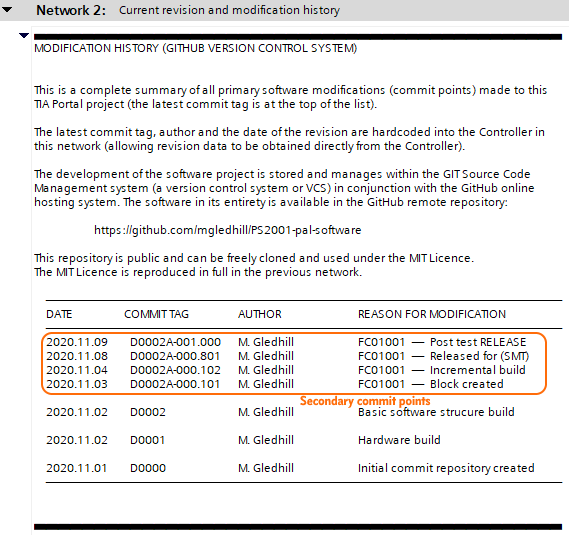
The network comments contain considerably more information about the revision and its point in the software development workflow, under the control of the VCS.
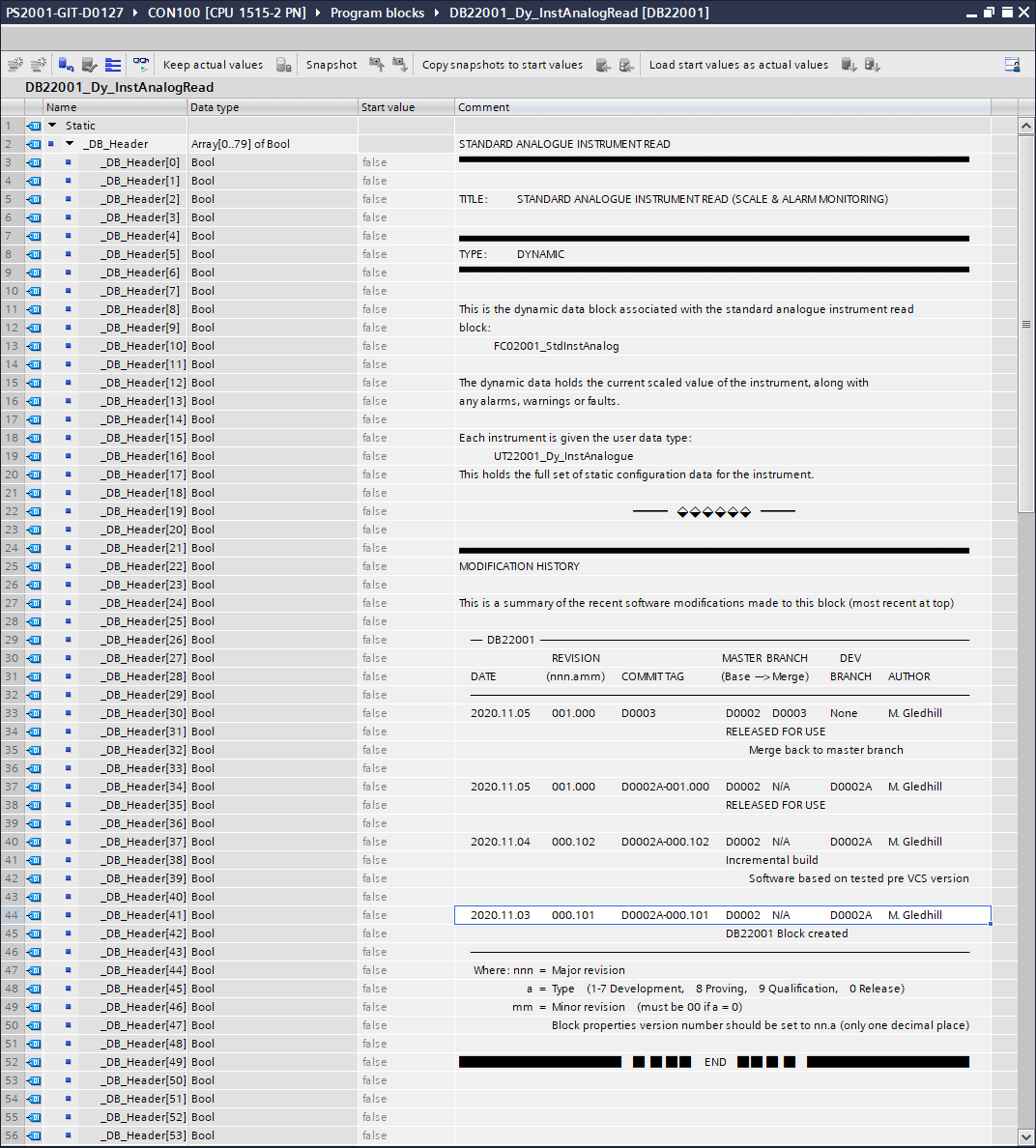
Figure 3.10 show an example of the network revision comments. These comments represent the example shown in § 3.5, reproduce in Figure 3.11 below.
Figure 3.10 Network comment revision information
Figure 3.11 Example development branch, merge to master
Examining the network comments in more detail:
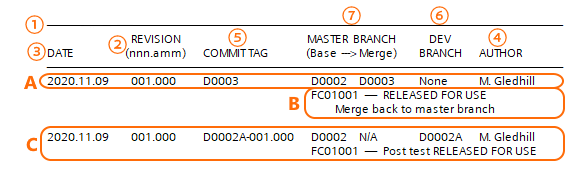
Figure 3.12 Network comment revision information details
Point 1 is the start of the revision table
The information given in point 2 to 4, is identical to the information hardcoded into the module:
Revision number (incorporating status information)
Revision date
Revision author
Point 5 is the commit tag given to the commit when the software is added to the repository.
Point 6 identifies the development branch upon which the changes were made, only the first six characters are required (everything before the dash) to uniquely identify the branch.
Point 7, the MASTER BRANCH contains two entries: BASE and MERGE.
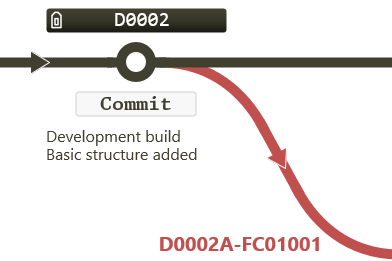
The BASE entry records the commit point on the master branch from which the development branch spurs away, in this example it is at the commit point with tag D0002:
Figure 3.13 Base commit point (where a branch diverges)
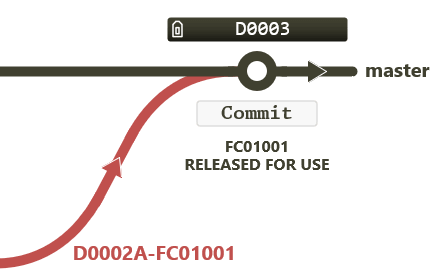
The MERGE entry records the commit point tag at which the branch re-joins (merges) with the master branch. In this case it is at commit tag D0003:
Figure 3.14 Merge commit point (where a branch merges)
The BASE/MERGE entries are complete in Figure 3.12 for the final entry in the revision list (entry A), but the MERGE entry reads N/A (not applicable) in the preceding entries (entry C for example). The reason for this is that while the software is being developed on the D0002A branch, further developments may be taking placed on other branches (see § 3.9 for an explanation of this), and these branches may merge back to the master branch before this one (effectively occupying the next commit point tag).
It is not until the development branch is complete, and ready to be merged back to the master branch, that the final MERGE commit point tag will be known.
3.6.2
Recording revision numbers within a data block
Data blocks, both static and dynamic, like programmable blocks, have the revision information both hardcoded in the block and stored (with additional information) within the header comment area of the data block.
If the data block is being developed as part of the development of a software module, the development branch will have a label associated with the programmable block rather be directly associated with the data block (in the previous example, the branch was called D0002A-FC0100, labelled for the software module being developed: FC01001).
Data blocks are to some extent independent of the standard blocks with which they are associated, a new device may be added to a project and the associated data blocks will be modified (and their revisions changed) to accommodate it. The standard module within which the data blocks are used will not change.
If the data block were the sole focus of the development branch it would be permissible to label the branch for the data block in question (e.g. D0002A-DB21001).
Hardcoded DB revision data
The hardcoded information is stored as the first non-header variable of the data block. As with programmable blocks, the variable is called revInfo, and is again of the user data type: UT01000_St_SysRevision; this being the same data type used for programmable modules (see Table 3.3).
An example of this is shown below:
Figure 3.15 Hardcoded data block revision storage variable
Header comment DB revision
The network comments for a DB contain the same type of information (and in the same format) as programmable blocks (see § 3.6.1).
Data blocks do not have the facility for network comments that is available to programmable blocks; however, all PAL data blocks are configured with a header array with variable name DB_Header, this is an array of 80 Boolean values and is used purely as a comment area for the data block. The revision information is contained within the comment area of this DB_Header array.
An example of this is shown below:
Figure 3.16 Header comment revision information
The header comments are applied in exactly the same way as the network comments of a programmable block (see Figure 3.10).
The DB_Header array is of a finite size and cannot accommodate unlimited comment information (unlike a programmable block), where the revision information becomes longer than the available space, the oldest revisions will be removed from the list (the revision information will still be recoverable from earlier commit points affecting that particular block).
3.6.3
Recording revision numbers within a User Data Type (UDT)
UDTs, both static and dynamic, have only hardcoded revision information and this holds only the current revision information, identical to the hardcoded data in a data block.
The hardcoded information is stored as a variable of the UDT. As with data blocks, the variable is called revInfo, and is again of the user data type: UT01000_St_SysRevision; this being the same data type used for programmable modules (see Table 3.3).
UDTs, are closely associated with a standard module, and any change to a UDT will cause a subsequent revision change within the associated module (after all, only the module can do something with the variables in the UDT). It is however, possible, and indeed common, for a change to the software module to have no effect on the UDTs associated with it.
For consistency, whenever there is a change to a UDT or to the standard module that uses that UDT, the UDT revision will be changed to match the released version of the standard module (even if there has been no change to the UDT). For example, if a standard module is changed in some way and released at revision 002.000, all the UDTs that are associated with it will also be released at revision 002.000.
In short, the released UDT revision should always match the revision of its parent software module.
3.7
OB1 module revision numbers
Each development branch concentrates (typically) on a single software module (usually a standard module that will form part of the PAL) with its associated data blocks and UDTs.
For development purposes, all these blocks are modifiable on a single development branch and are unlikely to be modified by work on other development (or any other) branch. In essence, the development takes place in isolation on its own branch.
The revision of the software module under development, its data blocks and UDTs are all recorded individually in each of the various blocks.
In addition to the module being developed, the main programme organisation block. OB 1 (more formally identified in the PAL as OB00001_IntINrmMainProgram), will also be modified, specifically to call the module under development.
OB 1 is considered a special block in the Practical Series Automation Library (and in terms of most Siemens Controller software). It is the block that executes all the rest of the controller software.
As such it contains information about the whole project rather than just a software module. The revision data is also project specific (not module specific).
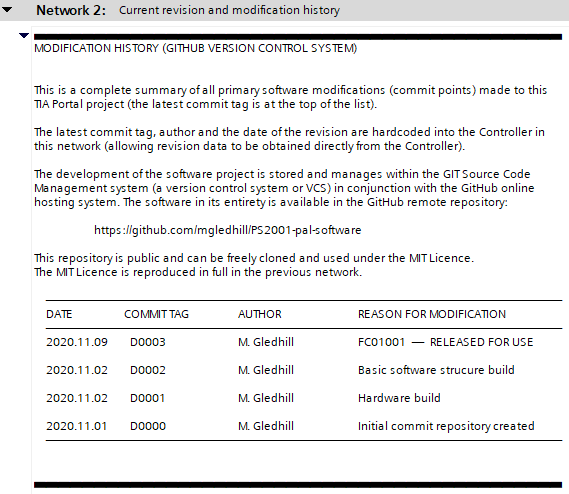
OB 1 Network 2 contains the current revision of the whole software project (rather than of a particular block). In this regard the revision information contained in OB 1 does not follow the nnn.amm format specified for other programmable blocks; it simply adopts the commit tag at the time of the commit, consider the previous example. In its final stage (at the point of merging the development back to the master branch), it had the following series of commit tags:
Figure 3.18 Example development branch, merge to master
At each commit point on the development branch, the OB 1 network comments would have recorded each commit, this can be seen below:
Figure 3.19 OB 1 revision history on the development branch
Here, it can be seen that the comments reflect the secondary commit points made on the development branch.
Each revision should be restricted to just one line in OB1.
Once the development branch has been merged back to the master branch, there will be an additional primary commit to reflect this; at this point, the secondary commits will be removed from OB 1.
The revision history contained in OB 1 at each primary commit point only shows the primary commit information. In this case the primary commit is D0003 and the OB1 revision history is as follows:
Figure 3.20 OB 1 revision history at a primary commit point
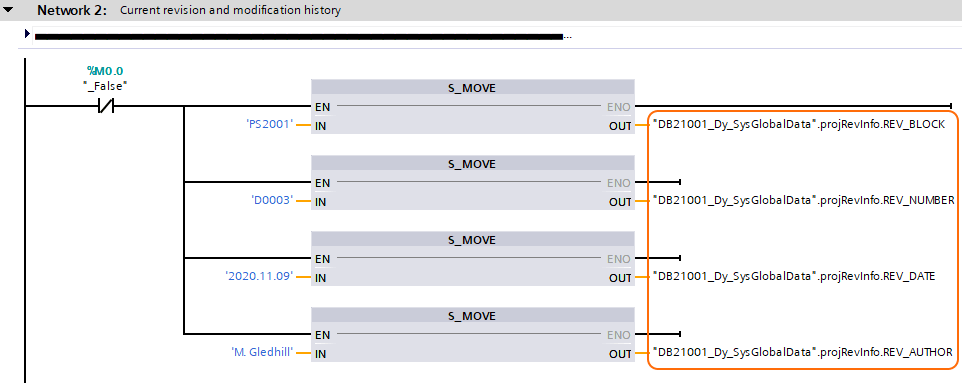
The OB 1 revision history is hardcoded in network 2, this is similar to the mechanism used for all other programmable blocks (see § 3.6.1), the difference is that the revision information is stored in a data block (all other programmable blocks store the revision information for the block in temporary storage within the block).
This can be seen here:
Figure 3.21 OB 1 hardcoded revision information
The block number is replaced with the project number (PS2001 in this case), and the S_MOVE outputs are all passed to variables within data block DB21001.
OB 1 comments are slightly more complicated when multiple development branches exist, see § 3.10.2.
Where a commit is made directly on the master branch (for minor modification or to change ancillary files), the revision of OB1 and the filename of the project must also change to reflect the new commit point tag
3.8
Commit points and filenames
The TIA Portal project, is saved at each commit point (both primary and secondary); the project is saved under a new filename at each commit point.
The filename is of the following format:
PS2001-PAL-<commit tag>
For example, a primary commit filename might be PS2001-PAL-D0002 and a secondary commit file name PS2001-PAL-D0002A-000-101.
In the filename, any full stops (.) present in the commit tag field are replaced with dashes (-).
The following shows the individual filenames for each of the commit points shown in the example of Figure 3.18, the filenames are shown in green:
Figure 3.22 Commit point filenames
The project is saved at each commit point under the its new file name (see above), the project is also be archived at this point, using the archive facility within TIA Portal (project → archive), this will produce a .zap16 file with the same filename as the TIA Project. This is a compressed (zipped) file that can be used to recover the entire project. These .zap16 files are all stored as archives on the Practical Series of Publications network accessible storage (NAS) drives (section 5 explains the various folder structures and storage locations used by the Project).
3.8.1
OB 1 and filenames
The project filename is stored in network 1 of OB 1. This must be updated prior to each commit being made (in much the same way as the project revision, see § 3.7).
An example of the OB 1 network 1 project name is shown below: